Retrieval-Augmented Generation (RAG) is a technique that combines a language model’s text generation ability with an external information retrieval process.[1] In a traditional setting, an LLM (Large Language Model) generates answers using only the knowledge encoded in its training parameters. RAG, by contrast, allows the model to “consult” external data sources (documents, databases, web content, etc.) at query time. This means the model’s responses aren’t just based on what it “remembers” from training – they can include up-to-date, factual information fetched on the fly. Essentially, if a standard LLM is like a student taking a closed-book exam (answering from memory), a RAG system is like an open-book exam, where the student can lookup answers from a reference text. This dramatically improves the reliability of its answers. Use cases include offering chatbot access to internal company data or providing factual information solely from an authoritative source.
Workflow of RAG
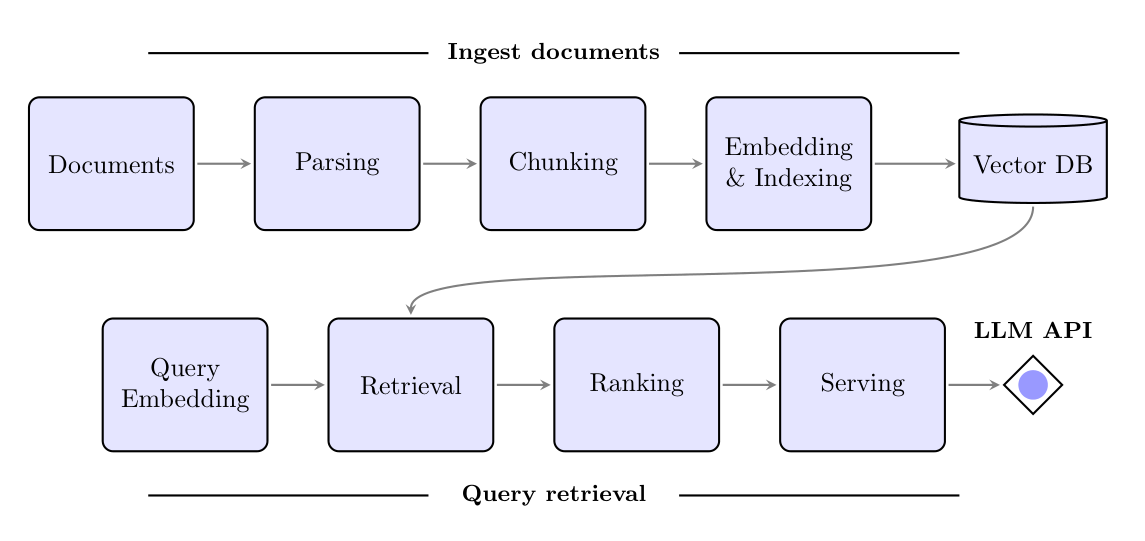
At a high level, a RAG system consists of two core parts working in sequence: a retriever and a generator.[1] When a user poses a query, the system doesn’t directly pipe it into the LLM as in a normal chatbot. Instead, it first passes the query to the retrieval component, which searches a designated knowledge base for relevant documents or facts. This knowledge base could be a collection of company documents, a snapshot of the web, a database, or any text corpus. The retriever finds the most pertinent snippets (using methods we’ll discuss shortly) and returns them. Next, the generation component (the LLM) takes both the user’s query and the retrieved text as input, and uses this augmented input to produce a response. Because the model now has supplemental knowledge related to the question, it can craft a far more informed answer than it could from its built-in training data alone. This interplay – retrieve, then generate – is the defining loop of RAG.
Schematic of a Retrieval-Augmented Generation workflow. A user’s prompt is first sent to a retrieval module that fetches relevant data (from internal knowledge sources or databases), and the language model then conditions its answer on both the prompt and the retrieved context. In practice, a RAG pipeline often involves a few moving pieces. The retriever usually relies on an embedding model that converts textual documents into vector representations (so that semantic similarity searches can be done efficiently). Given a query, the system compares the query’s embedding to those of documents in a vector store or index, retrieving passages with high similarity (i.e. likely relevant content). In some implementations, a reranker model may further refine these results by scoring which of the retrieved passages most directly answer the query. Finally, the top-ranked information is provided to the LLM as additional context (often just by prepending the text or inserting it into a prompt) and the LLM generates a final answer that references this information. This “augment then generate” approach means the model isn’t limited to its static training knowledge. It can dynamically pull in fresh or niche information as needed – a process sometimes called knowledge expansion, since the model’s effective knowledge is expanded by the retrieved content. The result is a system that behaves like a knowledgeable assistant: it first “researches” the query and then responds, leading to answers that are both articulate and backed by evidence.
Significance in NLP
Integrating retrieval with generation brings significant benefits to NLP applications, especially those that require factual accuracy and current information.[2] Factual correctness is greatly improved because the language model can base its output on real documents. The model can literally quote or summarize facts from the source material, which enhances accuracy and reduces hallucination. Studies and practice have shown that RAG effectively grounds the model’s responses: instead of guessing, the model uses retrieved evidence, so it’s far less likely to “lie” or invent details. By cross-referencing its output with source documents, a RAG system ensures a higher level of truthfulness. This grounding also makes it easier to provide citations or references in the response, which is useful for user trust.
Another major advantage is access to up-to-date and specialized knowledge. Traditional LLMs have a knowledge cutoff (they only know information from their training data, which might be months or years old). RAG enables the model to answer questions about recent events or very specific domains by fetching the latest relevant data. The system can pull in “fresh” information (say, last week’s financial report or the latest research papers) at query time. This makes RAG indispensable for knowledge-intensive tasks – for example, in medicine or law – where the relevant facts might not have been part of the model’s original training. Rather than retraining or fine-tuning a model on a huge corpus of domain text, RAG lets a general model query that corpus as needed. As a result, the model can adapt to different domains or contexts on the fly. Need the AI to act as a medical assistant? Point the retriever at a medical journal database. Tomorrow, use the same model for legal questions by pointing it at a law library. RAG provides a flexible way to inject domain knowledge without permanently changing the model.
Overall, retrieval augmentation makes AI responses more reliable, relevant, and context-aware.[2] It dramatically cuts down on confident-sounding mistakes by ensuring the model has the right information at hand. It also allows the AI to handle queries that are open-ended or reference-heavy, which pure generative models struggle with. In fact, for many knowledge-intensive tasks, RAG-like architectures are emerging as the superior approach. Tasks such as open-domain question answering, factual chatbots, and research assistance benefit because the system can always fetch the necessary details rather than hoping the model “remembers” them. This leads to responses that are both detailed and contextually relevant, providing the user with correct information and nuanced context that a standalone model might miss. In summary, RAG marries the fluency of large language models with the accuracy of a search engine – a powerful combination for real-world AI applications.
Technical Aspects of RAG
BM25 and Sparse Retrieval
One of the fundamental techniques in the retriever’s toolkit is BM25, a term-based retrieval algorithm originating from traditional information retrieval (the “Okapi BM25” model).[3] BM25 is essentially an advanced variant of the TF-IDF ranking formula that many search engines have used for decades. In simple terms, BM25 scores documents for a given query by looking at how often the query terms appear (term frequency), while also considering how rare those terms are across the whole collection (inverse document frequency) and adjusting for document length. This means a document that contains the query keywords frequently (especially if those words aren’t common in other documents) will get a higher score, but BM25 smartly dampens the effect of repeating the same word too many times (diminishing returns) and of very long documents (which naturally have more words). The result is a relevance ranking that often matches intuitive keyword search: if you ask for “neural network training,” BM25 will favor documents that mention those exact terms in a significant way.
Despite the rise of neural semantic search techniques, BM25 remains highly relevant and is widely used as a baseline and component in modern RAG systems.[3] One reason is that lexical matching is precise – if the user’s query contains a rare keyword or a specific name, BM25 will almost certainly catch documents with that exact term, whereas a purely semantic (embedding-based) search might miss it if phrased differently. BM25 is also efficient and well-understood, making it easy to deploy at scale. Many applications actually use a hybrid approach: first use BM25 (sparse search) to quickly narrow candidates, then use vector-based retrieval to refine, or vice versa. In practice, combining BM25 with vector similarity can yield the best of both worlds, since BM25 provides a strong precision boost for exact matches and anchors the search in key words. For example, a RAG system might retrieve some documents via dense embedding similarity and also some via BM25, then merge and rerank them. BM25’s enduring popularity is evidenced by its integration in many open-source RAG tools and search engines (who often have BM25 as the default ranking function). In short, BM25 continues to be a robust workhorse for keyword-based retrieval, ensuring that RAG systems don’t overlook the obvious relevant texts while chasing semantic meaning.
Reranking Models for Improved Precision
Even after using advanced search algorithms (whether BM25 or neural retrieval), the initial list of results might not be perfectly ordered – some retrieved passages will be more relevant than others.[3] Reranking models serve as a second-stage filter that re-orders (or filters) the candidate set to improve precision. A reranker is typically a trained model (often a transformer like BERT) that takes a query and an individual retrieved passage as input and produces a relevance score. Unlike the first-pass retriever (which might use simple cosine similarity in the embedding space or BM25 scores), a reranker can perform a deeper, contextual comparison between the query and each document. For instance, a cross-encoder reranker might concatenate the query and a passage and use an attention-based model to gauge how well the passage actually answers the query’s intent. This extra computation is more expensive, but it yields a finer-grained relevance judgment.
In a RAG pipeline, the reranker sits between retrieval and generation: the retriever might pull, say, 50 candidate chunks, and then the reranker model scores these and picks the top 5-10 to feed into the LLM. The role of rerankers is critical for precision – it ensures the generation component gets the best information, not just okay information. By prioritizing the most pertinent bits of text, rerankers boost the quality of the final answer. In fact, as one reference notes, reranking is one of the simplest ways to dramatically improve the performance of a retrieval system.[3] The trade-off is that rerankers add latency (they essentially run an inference for each candidate document) and computational cost. But since they only operate on a limited number of candidates, this cost is usually manageable, and many applications find it worth the improvement in answer accuracy. Rerankers can be as simple as a BERT-based classifier or as advanced as large seq-to-seq models that score answer likelihood with a given context. There are also specialized rerankers (e.g. based on MonoT5 or other fine-tuned models) that are available off-the-shelf. Overall, reranking models act like a knowledgeable editor – from the rough stack of relevant papers the retriever found, the reranker picks the few that truly have the answer, thus feeding the generator high-quality, focused context.
Chunking Strategies for Document Segmentation
Feeding entire documents into an LLM is usually impractical due to context length limits and irrelevant content.[3] Chunking is the strategy of breaking documents into smaller pieces (chunks) so that relevant portions can be retrieved and presented to the model. How you chunk the data can greatly affect a RAG system’s performance. Intuitively, chunks need to be large enough to contain a meaningful piece of information (a complete thought) but small enough to be specific and to fit in the prompt easily. If a chunk is too large (imagine embedding a full chapter as one chunk), the retrieval might find that chunk relevant overall but half of its content could be unrelated fluff, and the LLM has to wade through a lot of text (which could introduce confusion). If a chunk is too small (say, one sentence), you might lose important context and end up with fragments that don’t stand on their own. In essence, “size matters” in chunking: include too much and you lose specificity; include too little and you lose context.
Several chunking strategies have emerged to balance this.[3] A straightforward approach is fixed-size chunking – e.g. split every document into 200-word or 1000-character chunks. This works and is easy to implement, especially for uniform text like articles or FAQs. However, fixed chunks can cut off in the middle of a topic or sentence, so many implementations use a sliding window with overlap: for example, take 200-word chunks but slide the window by 50% each time so that consecutive chunks share some content. Overlapping chunks help preserve context that straddles chunk boundaries (so that if an answer lies at the border, it’s likely to be fully contained in at least one chunk). Another strategy is semantic or structure-based chunking – instead of arbitrary sizes, split by logical units like paragraphs, sections, or headings in the text. For instance, you might break a documentation page at each top-level bullet or each header, ensuring each chunk is a semantically coherent section. This method respects natural boundaries (so you don’t split sentences or closely related sentences) and often yields chunks that align with how humans would retrieve info (e.g. a Q&A pair, a definition, a code example block, etc). It can, however, result in varying chunk sizes. There are also adaptive ML-based chunkers that attempt to decide optimal chunk points by analyzing the text (though this can be complex and compute-heavy).
Choosing the right chunking strategy often depends on the use case and the data. As a general guideline, experts have found that using smaller, self-contained chunks that capture a single idea or answer tends to work well.[3] A practical approach is to iterate: if chunks are too big and retrievals seem broad, try making them smaller; if you lose context, introduce overlap or merge small chunks. In any case, chunking is a critical pre-processing step in RAG – it directly impacts what the retriever can find. Good chunking ensures that when the system retrieves text, it gets precisely the information needed to answer the query, with minimal extraneous text. That way, the LLM can focus on the most relevant content, and the risk of it getting distracted or misled by irrelevant info is reduced. Thus, chunking and retrieval go hand-in-hand: a well-chunked knowledge base makes the retriever’s job easier and the generator’s answers better.
Open-Source Frameworks
In response to the growing popularity of retrieval-augmented techniques, many open-source frameworks have emerged to simplify building RAG systems. Here are a few of the most widely adopted ones:
-
LangChain – An open-source framework (in Python and JavaScript) that provides a high-level API to chain together LLM calls and retrieval steps.[2] LangChain popularized the idea of prompt orchestration and “agent” behaviors for LLMs. It allows developers to construct RAG pipelines as sequences of components (e.g. embed text, search vector DB, then feed into GPT) with minimal fuss. It has an extensive ecosystem of integrations (various vector databases, LLM providers, tools) and an active community, making it a go-to for rapid prototyping of RAG applications.
-
LlamaIndex (GPT Index) – An open-source library specifically geared towards connecting LLMs with external data sources.[2] LlamaIndex provides tools to ingest documents (from PDFs, Notion, SQL databases, etc.), “index” them in structures suitable for retrieval, and then query those indexes with LLMs. It supports building hierarchical indexes, using keyword tables, vector stores, and more. Essentially, it abstracts the retrieval layer so you can treat your documents as an external memory for the LLM. The project also offers a managed SaaS (LlamaHub/LlamaCloud) for more advanced features, but the open-source core is very useful for building custom knowledge chatbots and research assistants quickly.
-
Haystack – A robust end-to-end framework by deepset AI for developing production-ready RAG systems.[2] Haystack is modular, allowing you to plug in components like document converters (PDF to text), retrievers (BM25, DPR, embeddings), readers/generators (e.g. question-answering models), and even rerankers in a pipeline fashion. It also provides out-of-the-box support for popular backends (Elasticsearch, OpenSearch, FAISS, Pinecone, etc.) and has features for feedback loops and evaluation. Haystack has been widely used in industry for building search-driven chatbots, QA systems, and even domain-specific assistants, thanks to its flexibility and scalability (it’s built with a production mindset, so you can scale components separately, cache results, etc.).
These are just a few examples. The open-source RAG ecosystem is giving developers plenty of choices to quickly stand up a retrieval-augmented generation workflow without reinventing the wheel.
RAG Offerings from Azure, Google, and AWS
Major cloud providers have incorporated RAG capabilities into their AI service offerings, enabling developers to leverage retrieval augmentation as a managed service:
-
Microsoft Azure – Azure offers Azure AI Search and Azure OpenAI Service, which together facilitate RAG. In fact, Azure has a feature called “Azure OpenAI on Your Data” that allows you to easily connect OpenAI’s GPT-4 or GPT-35-Turbo models to your own enterprise data sources. You ingest or connect your documents (which Azure can automatically chunk, index, and embed into an Azure search index), and then via a REST API or SDK, you can ask questions in natural language. Behind the scenes, the service will generate a search query, retrieve relevant document snippets from the indexed data, filter and rerank them, and then feed them to the GPT model, which produces a grounded answer. Essentially, Azure provides an end-to-end pipeline in the cloud: data ingestion, indexing, retrieval, and generation are all managed. This makes it straightforward to build, for example, an internal company chatbot that knows your private data, without having to stand up your own databases – you point the Azure service at your SharePoint, blob storage, etc., and it handles the rest. Azure AI Search supports hybrid search (combining vector similarity with traditional search), and with Azure OpenAI, the retrieved content can be used in a prompt to the model. This integration is available through Azure’s APIs and also through a Studio interface that lets you configure a “chat” on your data in a few clicks.
-
Google Cloud (GCP) – Google has introduced the Vertex AI RAG Engine as part of its Vertex AI platform. This is a managed orchestration service specifically designed for retrieval-augmented generation workflows. Vertex RAG Engine simplifies the process of connecting a knowledge base to Google’s models that are available in Vertex AI. With a simple API, developers can provide a query and get back an answer that’s grounded in their documents, without manually handling the retrieval step. Under the hood, the RAG Engine can use Vertex AI Search (a scalable vector search service, also known as the Enterprise Search on Generative AI App Builder) to find relevant text, then feed those results into the model. Google emphasizes “grounding” AI responses in factual data to prevent hallucinations, and the RAG Engine is a product of that focus. It’s aimed at enterprise users who want reliable, up-to-date results from LLMs. In addition, Google Cloud has Generative AI App Builder tools that let you set up chatbots with RAG, and they offer pre-trained models (like the Gemini model) that can work with retrieved context. In summary, GCP’s offering provides an all-in-one managed solution for RAG: you get an API endpoint where you send a query, and Google handles retrieving from your indexed data and leveraging their LLM to answer with references.
-
Amazon AWS – AWS approaches RAG enablement through a combination of its services. Amazon Bedrock is AWS’s fully managed service for accessing foundation models (including Amazon’s Titan, Anthropic’s models, etc.) with a suite of capabilities for customization. Bedrock recently introduced “knowledge bases” integration, which allows hooking up external data to ground the model’s responses. This means you can connect Bedrock to, say, an S3 bucket of documents or other data stores, and the service will take care of embedding and retrieving information from those sources when you query the model (all “under the hood”). In parallel, AWS offers Amazon Kendra, which is an enterprise search service powered by machine learning. Kendra is often used to build RAG systems on AWS: it can index documents (with support for many document types and built-in connectors to common data sources) and provides a high-accuracy semantic Retrieve API that returns relevant passages for a query. Developers can use Kendra’s results as the context for an LLM (like one hosted on Bedrock or an open-source model on SageMaker). The Retrieve API can fetch a large number of top passages (up to 100) with semantic ranking, which is great for finding precise answers. AWS is essentially encouraging a modular approach: use Kendra (or even Elasticsearch/OpenSearch with vectors) for retrieval, and use Bedrock (or SageMaker JumpStart) for generation. They have published examples and notebooks demonstrating this integration. The benefit of AWS’s approach is flexibility – you can mix and match AWS services to fit your needs, and you maintain control of your data (which stays in your AWS environment). Whether using Bedrock’s managed RAG features or assembling your own pipeline with Kendra and SageMaker, AWS provides the building blocks to implement retrieval-augmented generation with enterprise-grade security and scalability.
Key Applications of RAG
RAG is powering a new wave of smart chatbots that can give accurate, up-to-date answers.[2] For example, customer support bots use RAG to pull answers from product manuals or FAQ databases, providing users with correct solutions with citations. Instead of the bot responding “I don’t know” or, worse, hallucinating an answer, it retrieves the relevant support article and then explains the solution in natural language. This is employed in documentation assistants (like the Databricks chatbot mentioned in a webinar) to help users navigate technical docs. Similarly, personal assistants (think an AI that helps you manage your calendar or research travel plans) use RAG to search your personal knowledge (emails, files) when you ask things like “When is my next dentist appointment?” and then answer based on that retrieved info.
For students, analysts, or scientists, RAG can act as a research assistant – you ask a complex question and the system retrieves relevant papers, articles, or textbook sections, then synthesizes an answer.[2] This is hugely beneficial in academia and R&D. For instance, a medical researcher could query a RAG system about the latest findings on a disease, and the system will fetch paragraphs from journals and use them to formulate a summary. Tools like Elicit and other literature review assistants use this approach. In educational settings, a RAG-based tutor can answer “Why does quantum tunneling occur?” by pulling the explanation from a physics textbook, thus giving a factually solid answer with rich detail, rather than a possibly incomplete summary from the model’s memory. These systems shine in open-domain question answering, where any factual topic might be asked – the retrieval step ensures the answer is grounded in source material.
More broadly, any task that is knowledge-intensive can benefit from RAG.[1] This includes fact-checking and verification – e.g. a journalist can use a RAG tool to verify a claim by having it retrieve relevant news and stats to confirm or refute the claim. It also includes report generation and summarization: RAG systems can compile information from multiple documents to produce a comprehensive report. For example, in a business setting, an AI system might retrieve snippets from quarterly reports, financial statements, and news articles to generate a summary of a company’s performance. Another use case is personalized recommendations in e-commerce or content platforms, where an AI uses retrieval of user-specific data (past purchases, browsing history) combined with a generative model to produce a natural language recommendation or summary (“Based on your reading history, you’ll love these articles…”). In the realm of virtual assistants, RAG allows the assistant to have up-to-date knowledge – consider a voice assistant that can answer “What’s the traffic like on my commute today?” by retrieving the latest traffic news, or “How did the stock market do this week?” by pulling data from a financial API, then generating a concise answer.
Challenges and Considerations
A straightforward Q&A with a single LLM call is typically faster than a RAG pipeline, which introduces additional steps (embedding the query, searching the index, possibly reranking, then generating with a longer prompt).[3] This extra processing can increase response latency. In real-time applications like chat, that delay needs to be managed. Techniques like caching frequent search results, using faster vector databases, or asynchronous retrieval can help, but there’s an inherent speed trade-off when using RAG. Essentially, the system is doing more work (thinking before speaking), and that can slow things down. Engineers have to optimize each stage – for example, keeping embeddings in memory, limiting how many documents are retrieved/reranked, etc., to make the experience seamless. The good news is that often one can use a slightly smaller LLM when using RAG (since the model doesn’t have to “know” as much itself), which can offset latency. Still, careful architecture design is needed to ensure RAG responses are delivered in a snappy manner.
A RAG system is only as good as its retriever. If the retrieval component brings back irrelevant or low-quality documents, the generator might produce an incorrect or off-base answer (or it might ignore the bad context, but then it’s back to relying on its parametric knowledge).[3] Ensuring high retrieval precision is therefore critical. This can be challenging if the knowledge base is very large or if the query is vague. One must choose the right retrieval method (dense vs. sparse or hybrid) and possibly tune it. It’s common to iterate on the indexing and query strategy to improve relevance – for instance, adding custom synonyms, or using a reranker model (as discussed) to filter out false positives. Moreover, the retrieved text might need preprocessing: e.g., if documents are long, make sure they were chunked in a way that the answer isn’t split up. Maintaining accuracy also means the knowledge base itself must be accurate and up-to-date – if it contains wrong or outdated info, the model will faithfully reflect those in its answer. In summary, one has to monitor and continuously evaluate the retriever’s performance. Techniques like feedback loops (where the system checks if the answer actually contains the query terms or answers the question) can catch some issues. But this remains a key consideration: the garbage in, garbage out principle – RAG must retrieve good info to generate good answers.
RAG shifts some burden from the model to the knowledge store, which means you need an infrastructure that can handle potentially large volumes of data and queries.[2] Indexing a large knowledge base (millions of documents) and serving similarity searches on it is non-trivial. It requires efficient vector indices, and sometimes sharding or distributed search setups. As your data grows, you have to ensure the retrieval stays fast and relevant – this might involve using approximate nearest neighbor search algorithms or clustering the data. There’s also the challenge of updating the index: if your knowledge base is frequently updated (e.g. news articles), you need a pipeline to continually ingest and embed new content. Many vector databases support dynamic updates, but one must consider the time it takes to re-embed large documents or re-index. From a deployment perspective, a RAG system can be more complex: you might be running an LLM on one side and a separate search service on the other, which adds system complexity and points of failure. Ensuring the whole pipeline scales (both the search component under heavy load and the generation component) is a key part of productionizing RAG. Cloud solutions (like managed vector DBs and scalable model hosting) can mitigate these concerns, but cost becomes a factor. In essence, teams must plan for both data scalability (lots of content) and request scalability (lots of concurrent queries) when designing RAG solutions.
Introducing external data into the generation process raises questions about privacy. In many applications, the knowledge base may contain sensitive or proprietary information. It’s crucial to have proper access controls – the system should not retrieve content the user isn’t authorized to see. This can be tackled by integrating permissions into the retrieval step (for example, some enterprise search tools like Kendra can filter results by user access level). Also, if using third-party APIs or services for retrieval, data encryption in transit and at rest is important to protect the content. Another consideration: when you send retrieved text into an LLM (especially if it’s a third-party model API), you are essentially exposing that content. Some providers have guarantees about not using your data, but organizations might still opt to use self-hosted models for very sensitive data. Bias and quality of data are also considerations – the model will mirror the perspective of whatever sources it retrieves. If your knowledge base has biased or one-sided information, the output will reflect that. Mitigating this might involve curating the data or having the model retrieve from multiple diverse sources (source triangulation). In summary, while RAG can improve accuracy, one must manage which knowledge is being injected and ensure it aligns with the use case’s security and quality requirements.
Recent Advancements and Emerging Trends
The field of retrieval-augmented generation is evolving quickly, and one notable trend is the rise of Agentic RAG.[5] In a standard RAG setup, the process is relatively static: retrieve once and generate. Agentic RAG introduces a more dynamic, agent-driven approach, where the system can make iterative decisions about retrieval and use of external tools. In practical terms, this means an AI agent (powered by an LLM with a certain “prompted” logic) might perform multiple search queries, call different knowledge sources, or even use tools like calculators or APIs before finalizing an answer. It treats the retrieval+generation pipeline as something that can be controlled with reasoning steps. For example, suppose a user asks a complex question that might require information from a database and the web. An agentic RAG system could decide: “First I should query the company database, then if I don’t find enough, I’ll try a web search.” The agent then combines results from both before responding. This addresses limitations of naive RAG which typically uses only a single source and a single shot retrieval. By incorporating AI planning and reasoning, agent-based RAG can handle multi-hop queries (questions that require combining info from multiple places) and validate information through multiple passes. It’s like giving the RAG system a bit of autonomy to figure out how to answer a question, not just answer it directly. Early research and surveys on agentic RAG highlight that it can significantly improve correctness on complex tasks, though it does introduce more complexity in prompt engineering and execution.
Beyond agentic approaches, there are other exciting developments: improved retrievers (learning retriever components end-to-end with the generator, so that the system as a whole gets better at finding what the model actually needs),[4] and hybrid retrieval techniques that intelligently mix keyword search, dense vectors, and even knowledge graphs. There’s also work on making LLMs retrieval-aware – for instance, models that can formulate better search queries themselves (an agentic behavior) or models that have been trained with retrieval in the loop (like the original RAG paper by Facebook, which trained the retriever and generator together).[1] Another trend is extending RAG to multi-modal content: e.g., retrieving images or diagrams relevant to a query and then having the model incorporate those (for now, models like GPT-4o can handle images, so one could fetch an image and feed its description to the model). Also, as context window sizes in LLMs increase (models with millions of token contexts are emerging), the line between retrieval and prompting is blurring – but even with huge contexts, retrieval is often required to select the right pieces of information to fill that context efficiently.
Conclusion
In summary, the RAG paradigm is moving towards more adaptive and intelligent retrieval mechanisms rather than a fixed one-shot lookup.[5] Agentic RAG exemplifies this by giving the model a kind of decision-making loop to interact with data sources, making the overall system more autonomous and robust in handling complex information needs. These advancements are pushing the envelope of what AI assistants can do – from just answering questions with a bit of help, to actively figuring out how to get the answer. It’s an exciting time, as these developments promise even more accurate, transparent, and versatile AI systems that can truly act as knowledgeable agents in service of users’ goals.
References
- 1.Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.T., Rocktäschel, T. and Riedel, S., 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33, pp.9459-9474. ↩
- 2.Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H. and Wang, H., 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2. ↩
- 3.Wang, X., Wang, Z., Gao, X., Zhang, F., Wu, Y., Xu, Z., Shi, T., Wang, Z., Li, S., Qian, Q. and Yin, R., 2024, November. Searching for best practices in retrieval-augmented generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 17716-17736). ↩
- 4.Shi, Weijia; Min, Sewon (2024). "REPLUG: Retrieval-Augmented Black-Box Language Models". "REPLUG: Retrieval-Augmented Black-Box Language Models". pp. 8371–8384. arXiv:2301.12652. doi:10.18653/v1/2024.naacl-long.463. ↩
- 5.Jiang, Z., Xu, F.F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., Yang, Y., Callan, J. and Neubig, G., 2023, December. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 7969-7992). ↩